Business analytics, or solving business problems through better use of data, is absolutely nothing new. But every decade or so new technology takes a big leap forward (client/server, web, etc.) and makes previous architectures obsolete. The next big wave of business analytics infrastructure is poised to start arriving this year.
Let’s take a look at an analogy from the history of computing. The first ever computer used for commercial business applications was created in 1951, called “Lyons Electronic Office” (LEO). J. Lyons and Co. was the Starbucks of its day, with high-volume tea rooms open 24 hours a day in key locations across the United Kingdom.

Lyons used LEO to solve a classic business analytics problem that organizations still struggle with today. They created a “Bakery Valuation application” that let the company optimize profitability and minimize waste by calculating exactly how many perishable buns and tea-cakes should be produced for the next day, based on the latest purchase data available. The very first application on the very first commercial computer was already all about business analytics.
LEO was the Exadata of its era – it was the biggest and best valve-based data-crunching machine available, with more than double the memory of its earlier rival, the Colossus. Sixty-four 5ft-long mercury tubes, each weighing half a ton, were used to provide a massive 8.75 Kb of memory (i.e. one hundred-thousandth of a today’s entry-level iPhone).
LEO provided breakthrough performance. It could calculate employee pay in 1.5 seconds, replacing skilled clerks that took 8 minutes. But LEO was already a dinosaur, about to be replaced by a completely new technology.
Leo used over 6,000 vacuum tubes to carry out calculations. They worked, but they were complex, large, slow, fragile, expensive, and generated massive amounts of waste heat and noise. Engineers could detect problems simply by listening to the cacophony of buzzes and clicks generated by the machine.

Then a technology breakthrough came along: the transistor. Invented in 1947, they were much simpler, much smaller, much cheaper, more reliable, and much, much faster than vacuum tubes. The first transistor-based computers appeared in 1953, radically changing what was possible with electronics, and rapidly consigned LEO to the dustbin of history.
And transistors were just the start of the revolution. As technology improved and miniaturized, integrated circuits were created to pack millions of transistors onto a single chip, enabling previously unthinkable possibilities (try to imagine a vacuum-powered iPad!).
I believe that we are rapidly moving from the “vacuum tube era” of BI and data warehousing to the “transistor era”. Today’s best-practice BI architectures are rapidly becoming obsolete, and we can already start imagining what the new “integrated circuit” opportunities of the future might look like.
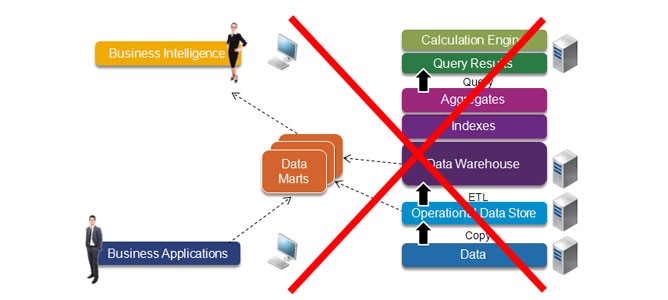
The last decade of “traditional best-practice” BI has been based on the following architecture:
- We start with business applications that gather the data we would like to analyze.
- We can’t do more than basic reporting against this data without slowing down the system, so we create a copy that’s typically called an “operational data store” or ODS.
- The ODS doesn’t store history, we want to analyze data from multiple systems, and the data is incompatible or incomplete, so we use ETL (extraction, transformation, and loading) technology to load data into database structures optimized for business intelligence – a data mart or data warehouse.
- Businesses want to store lots of information. To provide acceptable query times, the data warehouse must be optimized by the addition of specialized data structures, database indexes, and aggregate tables – all of which add to the size and complexity of the data warehouse.
- Business intelligence tools are made available to business people to access and display the information they are interested in. To provide better interactivity, an additional data cache is often created for a particular report or cube.
- Because this architecture is slow and unwieldy, organizations often create extra data marts for a particular business need.
The result is a vacuum tube: it works, and it’s the best alternative we have right now, but it’s slow, complex, and expensive.

Faced with these frustrations, several technologies have been used over the years to increase business intelligence speed and flexibility. Each has provided valuable progress, but has some downside that prevented it being used on a more general basis. A tipping point has arrived, however, and a combination of these approaches holds out the promise of a radically simpler BI architecture.
The most important is “in-memory processing”. All computer processing has always happened in live memory, but up until now, there have been severe limitations on how much data could be stored, and so all data has first to be retrieved from disk storage before it can be processed.
Over time, memory processing capabilities has expanded exponentially, in line with Moore’s Law, doubling every few years. But disk access speeds have been limited by real-world aerodynamics, and have increased only by 13x or so over the last fifty years. The result has been an ever-widening gulf between the speed of processing data and retrieving it from disk. Today, it can be up to a million times slower to get data from disk than from live memory.
 This leads to tough architecture choices. One way of imagining the consequences is to compare it to a chef cooking a meal. If — like on the TV cooking shows — all the ingredients are already prepared and sitting on the counter-top, it’s very quick and easy to create the meal. This is the equivalent of “in-memory processing” once all the required data is available.
This leads to tough architecture choices. One way of imagining the consequences is to compare it to a chef cooking a meal. If — like on the TV cooking shows — all the ingredients are already prepared and sitting on the counter-top, it’s very quick and easy to create the meal. This is the equivalent of “in-memory processing” once all the required data is available.
But imagine now that the chef doesn’t already have the ingredients ready. Given the slow relative speed of disk access, it’s as if the closest supermarket was on the planet Mars, and the ingredients had to travel months by rocket before each and every meal.
Database vendors have taken every approach possible to increase disk access speeds, for example by predicting what data is most likely to be needed and caching it in advance (the equivalent of pre-stocking a larder in the restaurant, full of the ingredients that are most requested). But the whole point of a data warehouse is to be able to ask any question — the equivalent of being able to order any meal in the restaurant — and so you have to go back to the supermarket on Mars on a regular basis.
Up until recently, it’s simply been too expensive to store data anywhere other than disk. But the price of memory has plummeted over the last two decades, and 64 bit addressing has radically increased how easy it is to access. Just ten years ago (when we first defined the current BI best practices) the price of one megabyte of live memory was around one dollar. Now it’s over a hundred times less: below one cent, and still falling fast. This is equivalent to something shrinking from the size of the Statue of Liberty down to a Chihuahua: it would be strange indeed if this didn’t have an impact on how we create our BI architectures.

If the whole data warehouse could be stored in-memory, we could make the whole system much faster and much simpler – and eliminate the need for disk-based storage altogether. We’d no longer have need for database optimizations like aggregates and indexes – and eliminating these simplifies the data loading process, and allows us to store more data in that limited, valuable memory space.

But in-memory processing alone only gets you so far – to get the full value of in-memory processing, we want to pack in as much data as possible, and to do that, we can turn to a complementary technology: column data stores.
Today’s relational databases are row-based: each new set of data is written into the next-available memory space. This is fast, which is essential for high-volume transactional applications writing to slow disks. But there are downsides for storing analytic data in a row-based structure, in terms of storage efficiency and query speed.

Let’s use an analogy to illustrate the difference between the systems: I employ a “row-based” filing system at home. I open each day’s mail, take a quick look, and then put it on top of a big pile in the corner of my bedroom. At one level, it’s an extremely efficient system: it’s very fast to “write” to the database, and if I want to find all the papers I received on a particular date (a “transaction”), I can find it pretty quickly.
But if I want to do some “analysis”, such as finding my last five bank statements, it’s slow and painful: I have to systematically go through the whole pile (a “full table scan”). I could make things faster by, say, adding yellow post-it notes to the corners of bank statements, so I can go straight to that type of document (a “database index”), but that would create extra work and complicate the system.
My (far more organized) wife uses a “column-based” filing system. When she receives her mail, she takes the time to sort out the documents and allocate them to separate folders. It’s initially slower to store information, but it’s much, much faster when she wants to find all her bank statements.
Column databases store data more efficiently, and allow greater compression, because you store similar types of information together. For example, I get paid the same amount each month, so rather than storing the same pay slip twelve times in the file, I could simply store it once, with a link to each month, and add an exception for my annual bonus. The result is that you can store between ten and a hundred times more data in the same physical space, shrinking the data warehouse back down to a size similar to the raw data used to create it (see diagram below). This in turn reduces the amount of memory you need to scan for each query and increases query processing speed.

Commercial column databases such as Sybase IQ have been around for a long time, and have proved their value, particularly in very high-volume data warehousing environments. But the extra up-front loading time, compared with the slow write-time to disks, has limited their use in the market.
Now let’s imagine combining the two technologies, with an in-memory, column database. Because it’s compact, we can now store the entire data warehouse in memory. And because it’s fast, loading times are no longer a problem. We now have the best of both worlds without the downsides of each: the equivalent of being able to store the whole supermarket in the chef’s kitchen.
But we haven’t finished yet. We can bring three other data warehouse optimization techniques into the mix: analytic appliances, in-database algorithms, and incremental loading.
 By building a massively-parallel machine specifically for data warehousing, we can again radically increase the speed we can access and manipulate data. In particular, column databases are very well adapted to parallelization: because each column is stored in a separate area of memory, aggregates can be efficiently handed off to a separate processor, or even partitioned across several processors.
By building a massively-parallel machine specifically for data warehousing, we can again radically increase the speed we can access and manipulate data. In particular, column databases are very well adapted to parallelization: because each column is stored in a separate area of memory, aggregates can be efficiently handed off to a separate processor, or even partitioned across several processors.
To go back to the filing analogy: it’s the equivalent of my wife and I both working on our finances. If we had to work off the same pile of “row-based” documents, we’d constantly be in each other’s way. But with separate “column-based” folders, my wife can look through the documents of one bank while I look through another, or we can split the folder in two and each look at one half of them (“partitioning”).
We can also radically improve query speed by doing as much work as possible directly in the database. Today, if you want to do some statistical analysis, you typically have to do a query on the data warehouse, extract a large set of data to a separate statistics tool, create a predictive model, and then apply that to your data.
To take an overly simplistic example: imagine you wanted to rank one million customers by their cumulative revenue. if ranking is available directly in the database engine, you only have to extract one line of data – the result – rather than a million rows.
Of course, by having all the required data in-memory, and with the support of massively parallel processing, we can imagine far more sophisticated operations than just ranking. For example, accurate profitability and costing models can require huge amounts of processing. Being able to do it directly in the in-memory database would take a fraction of the time it typically does today.
Using a separate appliance also allows us to simplify our architecture: we can add a BI server in the same machine, without the need for a separate local calculation engine.
Next, instead of finding and updating data values in our data warehouse, we’ll just incrementally replicate new data from the operational system as soon as it’s available, and add a time-stamp. For each query, we simply ignore any out-of-date data. The loading process becomes much simpler and faster: we can just add new data as it arrives without having to look at what’s already in the data warehouse. This also provides a big auditing and compliance advantage: we can easily recreate the state of the data warehouse at any point in time.
Since we’re only loading new data, and we can do so in real-time, we no longer need an operational data store, and can eliminate it from our architecture.

It’s worth noting at this point the virtuous circle created by these different technology advances working together. Different vendors in the industry typically concentrate on combining one or two approaches. Each provides an improvement, but combining them all is the real opportunity: together, they provide all the upside benefits while mitigating the downsides of each technology – and lead to the real tipping point, where you can realistically give up the disk-based storage.

Thanks to in-memory processing, column databases, hardware optimization, in-database calculations and incremental loading, we’re left with the “transistor” version of business analytics. It does the same thing as the previous architecture, but it’s radically simpler, faster and with a more powerful architecture.

This diagram represents the “new best practice” possibilities of the new generation of analytic platforms. But we can go even further, and start thinking about the “transistor” phase of analytics – what new things might be possible in the future?

If we add ACID compliance (a set of properties required for reliable processing of operational data), and the option of using row and/or column storage in the same database, then we could use the same platform for both transactional and analytic processing. Backup storage would be provided by solid-state devices, so you could always recreate your in-memory environment.
This would have several advantages. First, we’ve talked a lot about having a “single source of the truth” in the last decades of business intelligence – if the transactions and the analytics are happening off the same set of data, then we can get a lot closer to our goal.
Second, we get closer to “actionable intelligence”, the ability to provide people people with analytic information as a seamless part of their operational activities, in time to make a difference (e.g. predict that the store will be out of stock tomorrow, and arrange a new delivery, rather than just telling us that the store ran out of stock yesterday).
Third, the new architecture is surprisingly well adapted to real-world business applications, which typically require much more than simple read-and-write operations. Application designers would no longer have to create complex logic above the database layer to do things like budget allocations or supply-chain optimization – these could use the superior analytic power of the analytic engine directly within the new platform.

We could then extend this architecture – putting it in the cloud would make mobile business intelligence, extranets, and data collaboration (both inside the organization and across the “business web”) easier and simpler.
There are also enterprise information management advantages. For example, one common business frustration with BI has been how hard it is to compare corporate data stored in the data warehouse with personal or external data. Today, business people have to extract a large download from the data warehouse, and manually combine it with other data using Excel. This adds extra complexity and work, and leads to information governance issues.
With the new architecture, there’s no longer any need for painful staged uploads to the data warehouse – we can create a “sandbox” area in the analytic platform, let people upload their data in simple row format, and combine and analyze as they wish, using the same, standard, secure corporate infrastructure.
It also turns out that column databases do a good job of storing text data for easy search and retrieval, and other forms of data and algorithms (XML, hadoop) could potentially use the same infrastructure.
There’s one key thing to note at this point: the diagram seems to imply that “data warehousing” is no longer necessary. But nothing could be further from the truth. Reality is, and always will be, messy. The core need to transform, integrate, and model data, across a wide variety of different sources, is as important as ever.

Data integration, metadata, and data quality issues are business problems that don’t magically disappear with a new technical infrastructure. But we can use the power of the in-memory calculations to do enterprise information management in real-time, rather than batch. It becomes more practical to integrate data on the fly (“virtual data warehousing), and we can take the data quality algorithms we use today (fuzzy matching, comparisons to master data, etc.), and execute them as transactions happen. We can store both the raw data, and the “validated” or “corrected” values. This allows us to flexibly decide, at query time, how much reliability we need for a particular analytic need.
In conclusion
The last decade of BI best practice data warehouse architectures is rapidly becoming obsolete, as a combination of existing technologies comes together to provide a tipping point. Every vendor in the market includes some combination of in-memory, column databases, appliances, in-db calculations, map-reduce-type algorithms, and combining operations and analytics in their vision. The obvious conclusion is that the real vision is to use all of these technologies at the same time.
The new analytic platforms won’t magically cure everything that plagues today’s BI projects, but will lead to two big changes:
- It gives us more simplicity and flexibility, to be able to implement business analytics fast, without having to spend most of our time tuning the infrastructure for performance.
- It gives us the power of big data and real real-time performance, combining the best of operations and analytics to create new applications that simply aren’t feasible today.
Other resources:
- Gartner: “Data Warehousing Reaching Its Most Significant Inflection Point Since Its Inception”
- IDC: “What do a cluster of corporate events tell us about the specialty data warehousing market?”
- Merv Adrian and Colin White: “Analytic Platforms: Beyond the Traditional Data Warehouse”
- Hasso Platner: “A common database approach for OLTP and OLAP using an in-memory database” and book: “In-Memory Data Management: An Inflection Point for Enterprise Applications”
Comments
35 responses to “Why The Last Decade of BI Best-Practice Architecture is Rapidly Becoming Obsolete”
[…] in-memory approaches collapse the stack of traditional IT, industry experts like Gartner’s Donald Feinberg believe that in-memory systems can be simpler, […]
[…] The last couple of years have been spent talking about the big new technology possibilities in the analytics market that hold out the promise of making decades of best practice obsolete. […]
[…] possibilities in the analytics market that hold out the promise of making decades of best practice obsolete. Now it’s time to put those technologies into action. As Doug Henschen of InformationWeek says in […]
[…] analytics best practices architectures are quickly becoming obsolete – but the new best-practices have yet to be […]
Timo,
Hi. Don’t know if you remember me. A few years back, I contacted you about using one of your videos (data quality: “For the Sake of the Children”) in some internal communication about DQ at Compassion, which is a child sponsorship organization. Anyhow, I want to respond to your article saying how fully I agree with you and to suggest another tool to consider in your best practices. We’re doing a lot of work at Compassion with a data virtualization tool (see Rick van der Lans articles and books for more on Data Virtualization). Interestingly, one of the greatest benefits we have found in our DV tool is not actually data federation, which is its real bread and butter. Rather, where we’re getting the most value is from encapsulating business logic in reusable views of the data. These views can be used like virtual building blocks and, for small to mid-sized businesses, can be used to create something akin to a virtual DW. By that, I don’t mean the DW exists using the federated data. Rather, I mean the DW objects (your facts and dimensions) only exist as views on top of base data. Because this removes the need for ETL and physical tables to land conformed data in, it means DW development is extremely rapid. Obviously, reprocessing the data for each analytical query means extra processing overhead, but with the advances in database performance resulting from the changes you have outlined above, this really does become a tenable option. In fact, in the case of small to mid-sized businesses, virtually building a DW like this may be more cost effective than physically storing data in facts and dimensions.
Andy
Andy – 100% agree… you may want to take a look at SAP HANA Live, which provides an analytics metadata view of operational SAP systems, providing an “OLTAP” architecture (OLTP+OLAP), with full analytics on operational data, without any of the typical compromises…
[…] This idea is far from new (one of the first to tout this approach as a differentiator was TM1 by Applix in the 1990s). But the economics have changed radically since the advent of 64-bit systems, and in the last few years in-memory technologies such as SAP HANA have proved their worth helping radically speed up and simplify business user access to information. […]
[…] analytics is a big deal. As promised last year, it greatly simplifies application architectures, “collapsing the stack” and avoiding the problem shown in this this Best Practices in Application cartoon sent to me by […]
[…] wonderful coincidence, I first talked about LEO in a post last year entitled Why The Last Decade of BI Best-Practice Architecture is Rapidly Becoming Obsolete. I explained that in-memory technology is transforming the way we do analytics, and used the […]
[…] (1) In-memory databases. This idea is far from new (one of the first to tout this approach as a differentiator was TM1 by Applix in the 1990s). But the economics have changed radically since the advent of 64-bit systems, and in the last few years in-memory technologies such as SAP HANA have proved their worth helping radically speed up and simplify business user access to information. […]
[…] wonderful coincidence, I first talked about LEO in a post last year entitled Why The Last Decade of BI Best-Practice Architecture is Rapidly Becoming Obsolete. I explained that in-memory technology is transforming the way we do analytics, and used the […]
[…] wonderful coincidence, I first talked about LEO in a post last year entitled Why The Last Decade of BI Best-Practice Architecture is Rapidly Becoming Obsolete. I explained that in-memory technology is transforming the way we do analytics, and used the […]
[…] year, I presented at dozens of conferences, explaining the big changes to BI infrastructures brought about by new technologies (in-memory, hadoop, MPP, in-db analytics, real-time, etc.). And this year, I’ve presented dozens […]
[…] agree with everything Timo says here and in this related post, but, I would add two additional points which I think extend the analogy and cast a word of warning […]
[…] The second is the IT aspect of BI — what technology is used to help provide the business need. This obviously does change over time — sometimes radically. […]
[…] newer in-memory architectures like SAP HANA are eliminating a lot of the need for redundant layers, and making it easy to analyze detailed, on-optimized data sets. This, in turn, makes it easier to […]
[…] newer in-memory architectures like SAP HANA are eliminating a lot of the need for redundant layers, and making it easy to analyze detailed, on-optimized data sets. This, in turn, makes it easier to […]
[…] reducing layers for analytical scenarios picked up my fellow social ambassadaor Timo Elliott “Why The Last Decade of BI Best-Practice Architecture is Rapidly Becoming Obsolete“ and SAP Mentor Vijay Vijaysankar: “Is collapsing layers a good thing? Help me […]
[…] reducing layers for analytical scenarios picked up my fellow social ambassadaor Timo Elliott “Why The Last Decade of BI Best-Practice Architecture is Rapidly Becoming Obsolete” and SAP Mentor Vijay Vijaysankar: “Is collapsing layers a good thing? Help me […]
[…] time, there have been big and small technology improvements, but nothing truly disruptive (although new analytic platforms are […]
[…] an earlier post, I outlined why I think we’re on the brink of a real revolution in business analytics…. This post draws out some of the parallels with the shift from analog to digital image processing, […]
Interesting ideas, but I’m not sure I fully agree.
Performance Lag between Server and Storage: As Moore’s Law still is valid with multi-core CPU etc, the CPU “Performance” grows probably an order of magnitude faster than memory performance. Really In Memory Technology looking at it this way is just a cacheing strategy and would need to move from Main Memory to CPU Cache as time moves on. Not sure this solves any Business Problem.
Also I don’t see why In Memory Technology would make incremental loading any easier. It’s not like incremental processing would in any way be tied to In Memory Technology. Really what you’re saying here is that there is a need for more “Real Time” integration, and In Memory Technology could be a building block here. However as In Memory will be used on Systems which require patches in a world where accidents can happen, incremental can’t solve all issues here. I have to admit I have applied certain techniques to ensure data stays in memory as much as possible, however have not worked with a product which claimed to feature In Memory technology. But to me it appears, that we would still need to persist our In Memory Data, at least to have reasonable re-start times in a production environment. Looking at it this way means again In Memory Technology per se is really more of a cache strategy.
Fraud, next best activity etc pp are areas where BI / DWH and operational applications need to integrate very closely, and performance could be gained by In Memory echnology. But overall I don’t see how In Memory Technology would facilitate integration of complex system landscapes.
Timo – You are an established BI thought leader so am I to infer that the “traditional best practice” you refer to and list are what you have been advocating to you clients in the last decade?
Of course it isn’t. What you describe and list doesn’t reflect the world I have been working in either in my current role at Teradata, nor in my prior role as a colleague of yours at Business Objects.
That’s a shame. I’m always very cynical when someone has to paint the alternative into such a bleak position to enable their solution to sound relatively new and innovative. They try to lower the bar to jump over it so as to claim some kind of leadership. I regularly see examples of organizations achieving all the capability and benefits presented here.
Pitching “Today’s Best Practice Architectures” so inaccurately loses impact for any valuable points you raise, and there are plenty here. I also like the way some (but not all!) of the concepts are presented and the analogies drawn. It’s a good story and typically well presented.
MadMike – you’ve spoiled the story with mundane questions on things such as high availability. Why would a Data Warehouse need that? Answer – if it is to ever be a viable platform for actionable intelligence. A platform for true, game changing analytics and front line interaction. An Active Data Warehouse. That’s the world I work in.
MadMike – you reading the same article as the rest of us?
Not sure where Timo has bad mouthed any vendor of any technology. All the vendors you mentioned Oracle, IBM, Microsoft and Teradata are all investigating and exploring in-memory systems.
Think it’s pretty simple – as memory gets cheaper it will make sense to store more and more in memory rather than on disk. HANA is pretty neat, but we’ll see a lot more options and architectures that mix cache, memory, SSD, traditional disk and near-line storage. Think Timo’s spot on – the architectures we currently think of as best practice will seem archaic in a very short time.
Peter
Interesting but mostly FUD. Your whole argument rests on two assertions: that main memory prices will fall so low that 10s of TBs are affordable and that columnar will compensate for whatever memory prices don’t do. Columnar is a current rage but by no means the only solution. Look at Vertica to see that they and others blend rows and columns when needed. A vast majority of columnar’s benefits can be achieved by compression, and in some ways columnar is a form of compression. OK, so you can stuff more in memory. Whoopdidoo. Oracle, DB2, and others are doing the same thing with production quality systems. When HANA matches the 20+ columnar and compression algorithms offered by Vertica, let us know.
Main memory prices are falling but never fast enough. Disk storage is many times cheaper and prices are falling faster. So the Big Data movement — you have heard of that and social media, right? — is driving the data deluge along with RFID, sensor networks, etc. You simply cannot buy enough memory and compress enough to make disk drives irrelevant for the next 10 years. So betting the business on HANA — which is your story, right — is betting on data marts of modest size. So while memory does come down in price, storage comes down faster and user expectations of hoarding data rises faster than the price of disk falls. If it didn’t, most of us would be out of a job soon. Come on, memory prices have fallen for 30 years but we still want more more more of everything. There’s nothing new here.
Most newbies with start-up products begin by bad mouthing the entrenched technologies. Most newbie start-ups fail or are absorbed by a larger vendor. We saw this with BOBJ federated queries, data mining, Hadoop, OO, and a dozen other new technologies that proclaimed the death of the dinosaurs. So far we have not seen any of these things displace any of the established products. Someone is always praying for an iPhone type solution that sweeps away the past. This is not one of those. So Oracle, DB2, SQL Server, Teradata, and all the ones you decried as dead will be here long after YOU are dead. Or have you noticed that there are over 200 database vendors now when just 5 years ago there were less than 40? Why should I believe SAP HANA is smarter than everyone combined?
in memory will become the latest hot box for data marts. That’s what your Gartner presentation forgot to mention: that you had to break up the work into 10 blades with limited, non-integrated data in each blade. That’s not all bad. And its not a data warehouse (go read your Inmon and Beyer). There are plenty of Microsoft Analytic Servers front ending a real data warehouse in this world, similar to what HANA can do today.
And I always notice that no one ever mentions that in-memory systems take forever to boot up. How long DOES it take to boot up 100TB compressed into memory? Let’s say it compresses 10 to 1. How long does it take to boot 10TB into main memory? What is the HANA architecture for that since you will need a lot of SSD disk to feed the PCI bus? I also never hear anything about HANA high availability.
My suggestion: Focus on the good things in-memory can do. If you have to bad mouth better products to get attention, your product isn’t worth buying. If the good things your product does are worthwhile, then why not talk about that? Give us real performance figures, not some faked out benchmark against a 5 year old machine or a vendor that didn’t know they were being bench marked.
This whole thing was FUD.
Ofcourse it matters how data is stored in RAM
Compared to io, ram is fast, but compared to your CPU cache, RAM is extremely slow.
Usually, in-memory columnar kernels are at least an order of magnitude faster then row based in memory.
The reasons are so vast and depend on many things:
– CPU memory hierarchy
– cache misses overhead in random access algorithms
– super scalar decompression inside the CPU cache
– vectorization & pipelined execution
– tight loops with Zero degree of freedom (no branching)
…. And a bunch of other issues… All start by storing data as arrays (or vectors that fit nicely into your cache). U cannot get that if you apply a tuple at a time iteration model in your memory (rows)
Eldad,
Absolutely — Thank you. I should have pointed out that reality is (as ever) much more complicated than the simplified view I gave….
[…] – Why the legacy BI ‘Best Practice Architecture’ is rapidly getting obsolete – a lot to with innovations around hardware, appliance and storage of data in last decade or so. […]
[…] The second is the IT aspect of BI — what technology is used to help provide the business need. This obviously does change over time — sometimes radically. […]
Hi Timo,
Regarding my site: can’t I have a little fun in this dried up world of BI and Analytics? What are we as a human race if we can’t have fun with our jobs and poke fun at ourselves?
Now, for those of you who do want to get serious about the Data Vault model and methodology, please feel free to: a) go to LinkedIn and search for the Data Vault discussions groups, b) read my bio on LinkedIn while your there, c) go to: http://dvUserGroup.com d) take a look at my blog: http://danLinstedt.com e) read my older blog posts on http://b-eye-network.com – all free resources, without the videos. And yes, people seem to enjoy the content, and I am sorry if you find it cheesy. There are plenty of other serious sites with all kinds of information that are available for free.
Again, I appologize if I offended anyone.
Please don’t confuse physical data modeling with physical infrastructure. They are two different things. Physical data modeling today, tries to overcome “physical infrastructure bottlenecks”, what I am saying is that as hardware, software, and data storage layers move towards RAM (on-board in-memory) architectures, that “physical data modeling” will become less and less important.
Physical infrastructure will always be important, and making it seemless to the users, and being able to take advantage of these things is incredibly useful going forward.
For instance: in a columnar appliance (up to a certain number of Terabytes), I don’t care, nor do I want to, about the “physical partitioning” of the data sets – this is something vitally important in a relational/row-based architecture. BUT as their is a convergence in the use of physical infrastructure by the different vendors, so too will there be a convergence in the “seemlessness” of the vendor solutions.
Now, OO has massive performance problems with big throughput and large data sets (the exception is that it is tremendously fast for single transaction access). Why? Because the coding layers of inheritance execute in serial, not in parallel. More importantly, OO has tightly coupled the “logical architecture” with the “physical execution style” (not the physical infrastrucure). Because of this, it relies heavily on the ability of the CPU’s to run the object inheritance serial data access routines (parent->child->child->child…..-> getPrivateData & return->return->return->return). It really has nothing to do with “column based vs row based” at all.
Hope this helps,
Dan Linstedt
Hi Timo,
Interesting thought processes, great post. I would tend to argue one point though: it’s not necessarily the column based databases that make this whole thing interesting….
Question for you to ponder: if you have a 100% in-memory database, will it really matter if it’s columnar or relationally stored? I personally don’t think so. I think in order to reach this grand vision, it will be necessary to let go of PHYSICAL data storage techniques.
Like you, I believe it is, was, and will be important to model your data – in a flexible, scalable and maintainable architecture – at least from a logical manner. And to that end, I would encourage you and your readers to take a look at the Data Vault Model and Methodology at: http://learnDataVault.com
However, I think when it comes to the physical storage components – columnar, row-based, structured, or something new we haven’t thought of yet, won’t make a difference. I think if it’s 100% memory storage, then it’s cell-based (value based), and what will matter is the performance of indexing, managing, and locating the data sets in the memory. So – physical memory access / performance will be important.
Cheers,
Dan Linstedt
Dan,
I’m not sure I quite get the point — you seem to say both that physical storage both is and isn’t important (last paragraph and second paragraph, respectively). Data modeling is primordial, but experience shows that if that physical infrastructure is too slow to provide good performance, it won’t provide effective BI. In-memory provides a big performance boost, but I don’t think it’s going to be enough, on its own, to provide both the simplicity benefits I talk about AND better performance.
I hear, for example, that Workday uses an in-memory object-based model, rather than tables at all — but that this presumably leads to some analytic bottlenecks…
Also — your site uses a really cheesy infomercial format that seems better suited to steak knives or blankets with sleeves than a BI methodology (“For over 20 years, I have been perfecting a secret system that people have heard about but do not know all the details”). Does it actually bring people to you?!
Great post Timo!
I think you are dead on in that the combination of these technologies are what will cause a complete shift in how we do data warehousing and BI.
Thanks,
Even
Hm you really do not understand Teradata….. agree with most of this and it is well presented… but some assumptions are generalised here.. Anyhow nice work. But! I expect in mem Db’s (which are so not new in any way)… have a long way to go scale wise, TCO wise… happy to be wrong!!
I completely agree in-memory calculations aren’t new — they’re considerably older than computer disks! The first OLAP solutions were all in-memory. I believe that the combination of in-memory AND column AND massively parallel, dedicated hardware AND getting rid of the disks, is what provides the tipping point to cheaper TCO. And even if I’m wrong today, I won’t be tomorrow — the cost curves are clearly heading that direction, which is why the whole industry is moving fast towards these solutions…