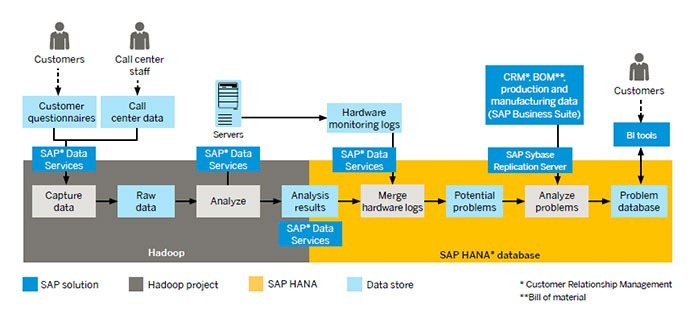

An example use case of Hadoop and in-memory systems extracted from the CIO guide to using Hadoop and SAP systems.
It’s Time For Two Worlds To Come Together
Earlier this year, I attended the Hadoop Summit in Europe, sponsored by Hortonworks. There were many excellent presentations at the conference, but the divide between “old” and “new” analytics was very clear. There were relatively few “traditional” companies presenting sessions, and those that were seemed faintly embarrassed to mention that they still had data warehouses.
The Hadoop use cases discussed were mainly new, standalone systems rather than integrations with with more traditional systems or analytic architectures. There were two notable exceptions.
 The first was by Alasdair Anderson, Global Head of Architecture for HSBC Global Banking and Markets, who presented on the theme of “Enterprise Integration of Disruptive Technologies.”
The first was by Alasdair Anderson, Global Head of Architecture for HSBC Global Banking and Markets, who presented on the theme of “Enterprise Integration of Disruptive Technologies.”
The bank needed a single data platform that could provide 360-degree views of clients, operations and products. To provide this, the team had been struggling with a complex, “brittle” architecture based on over 150 source systems, 900 ETL jobs, 3 data warehouses, and 15 data marts.
The resulting system was expensive, and too slow to meet the business needs: it took months or years to make changes. The team concluded that they needed a different way of doing things, one that would support more agile, parallel streams of development, without being disruptive.

HSBC decided to try using Hadoop, with the work done in Gaungzhou, China. The project was a big success:
- Hadoop was installed and operational in a single week
- The 18 RDBMS data warehouses and marts were ported to Hadoop in 4 weeks
- The time it took to run an existing batch job dropped from 3 hours to 10 minutes
- New data sources could be included, such as information about financial derivatives stored in .pdf format.
At the same time, however, Anderson explained how his analytics needs were maybe a little different from more traditional data warehousing. The focus of the project was fast-moving, “agile information” typically requiring several different iterations of analysis — and he explained that other parts of the business such as the retail banking division, did not have the same “funky needs.”
He admitted that HSBC “genuinely doesn’t know yet how the new architecture will combine with existing data warehouses in other regions”
The second notable presentation was Deutsche Telekom’s Jürgen Urbanksi on how to determine the right technical solutions for different types of enterprise data usage. He presented an overall view of different architectures and suggested questions that should be asked of the business in order to determine which technology was the best fit.
Hadoop was generally positioned as the “better” choice, although some of the comparisons with in-memory systems already seemed out of date (e.g. see slide below), and there was little discussion of how to integrate transaction systems (other than as simple data sources).

Integrating Hadoop With Existing Systems
The unspoken assumption of many of the delegates seemed to be that it was just a question of time before Hadoop gained the extra features that would enable it to take over all enterprise needs. Some seemed almost proud to ignore existing enterprise data architectures and any best practice learned over the previous decades (information governance springs to mind – this is still a very new concept for many organizations using Hadoop).
Many users of enterprise systems, on the other hand, seemed to have decided that Hadoop that only applies to web companies, or is restricted to refining semi-structured data before putting it into a “normal” data warehouse.
I believe that Hadoop is an incredible opportunity for most enterprises, both large and small. But I also believe that the big changes in enterprise architecture driven by in-memory systems, and the need for analytics close to transactions, mean that the ultimate best practice architecture will be one based on a combination of existing approaches, not just Hadoop alone.
With this in mind, ![]() SAP has teamed up with major Hadoop providers to combine the speed of in-memory computing with the storage power and flexibility of Hadoop.
SAP has teamed up with major Hadoop providers to combine the speed of in-memory computing with the storage power and flexibility of Hadoop.
SAP will redistribute and support the Intel Distribution Apache Hadoop and the Hortonworks Data Platform — InformationWeek journalist Doug Henschen explains the background to the deals in his article SAP Expands Big Data Push.
As part of the series of SAP “Big Data” discussions, Hortonworks CTO Ari Zilka explained why he felt that combining Hadoop and enterprise systems was the best of both worlds. And there’s more information about how real-life organizations are using Hadoop in their organization, in organizations as diverse as football and genetics, visit the SAP Big Data website.
For more detailed technical information about Hadoop can be integrated with traditional information architectures, check out the CIO Guide on Big Data: How to Use Hadoop With Your SAP Software Landscape.
Hadoop Summit Europe 2014
I’m looking forward to next year’s Hadoop Summit Europe in April, and thoroughly recommend you attend. It’s a great venue and a great crowd. And please vote for my presentation on “Real-Life Examples of Using Hadoop to Drive Business Innovation”!
Comments
2 responses to “Why Enterprises Should Be More Interested in Hadoop”
[…] attended the inaugural European Hadoop Summit in The Netherlands last year, and it was a real eye-opener to see how differently some people see the world of information and […]
[…] attended the inaugural European Hadoop Summit in The Netherlands last year, and it was a real eye-opener to see how differently some people see the world of information and […]